The Internet of Things is emerging as a model, and the network routing all the IoT data to the cloud is at risk of getting clogged up. “Fog is about distributing enough intelligence out at the edge to calm the torrent of data, and change it from raw data over to real information that has value and gets forwarded up to the cloud.” Todd Baker, head of Cisco‘s IOx framework says. Fog Computing, which is somehow different from Edge Computing (we didn’t quite get how) is definitely a new business opportunity for the company who’s challenge is to package converged infrastructure services as products.
However, one interesting aspect of this new buzzword is that it adds up something new to the existing model: after all, cloud computing is based on the old client-server model, except the cloud is distributed by its nature (ahem, even though data is centralized). That’s the big difference. There’s a basic rule that resumes the IT’s industry race towards new solutions: Moore’s law. The industry’s three building blocks are: storage, computing and network. As computing power doubles every 18 months, storage follows closely (its exponential curve is almost similar). However, if we graph network growth it appears to follow a straight line.
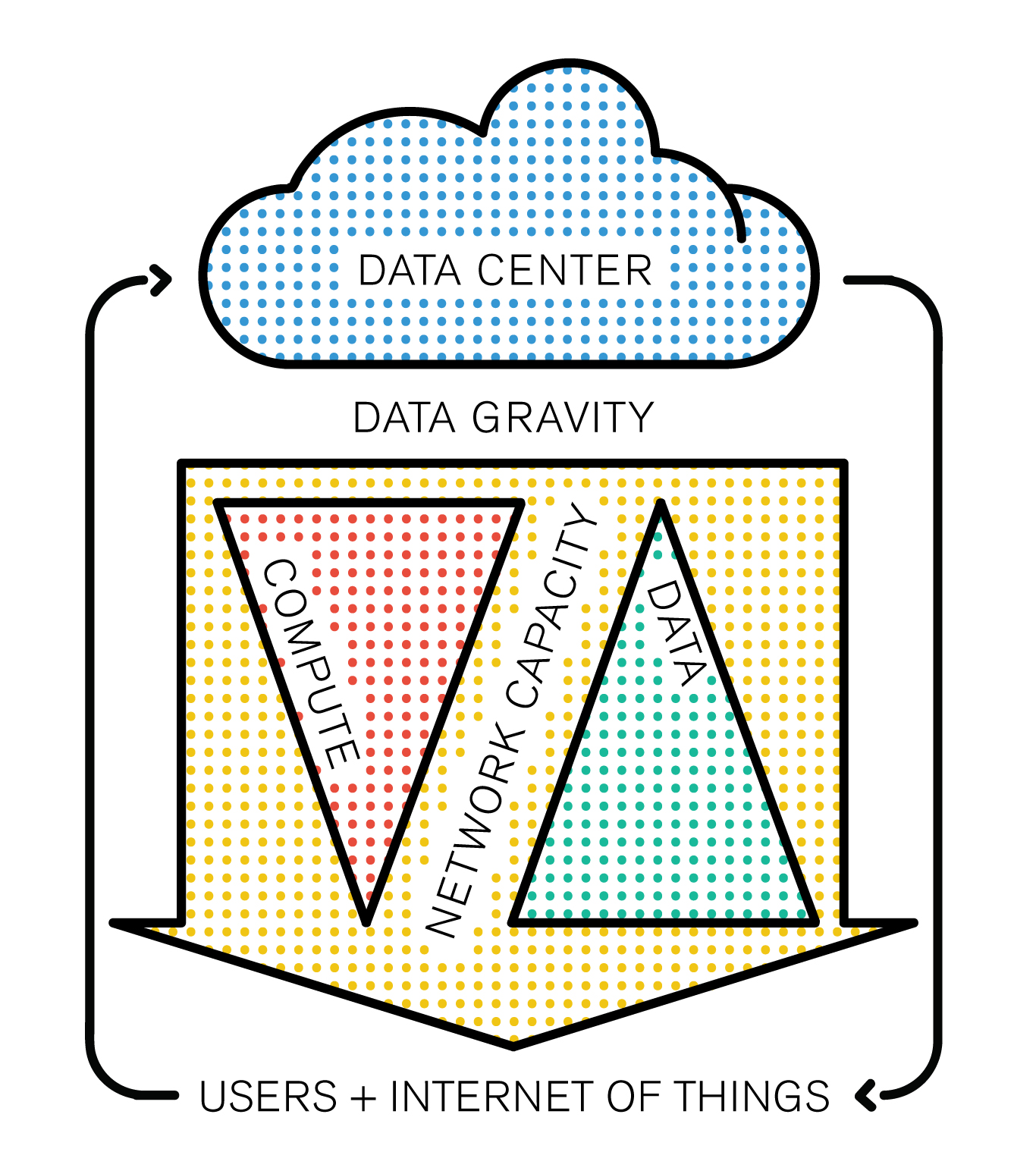
Network capacity is a scarce resource, and it’s not going to change any time soon: it’s the backbone of the infrastructure, built piece by piece with colossal amounts of cables, routers and fiber optics. This problematic forces the industry to find disruptive solutions, and the paradigm arising from the clash between these growth rates now has a name: Data gravity.
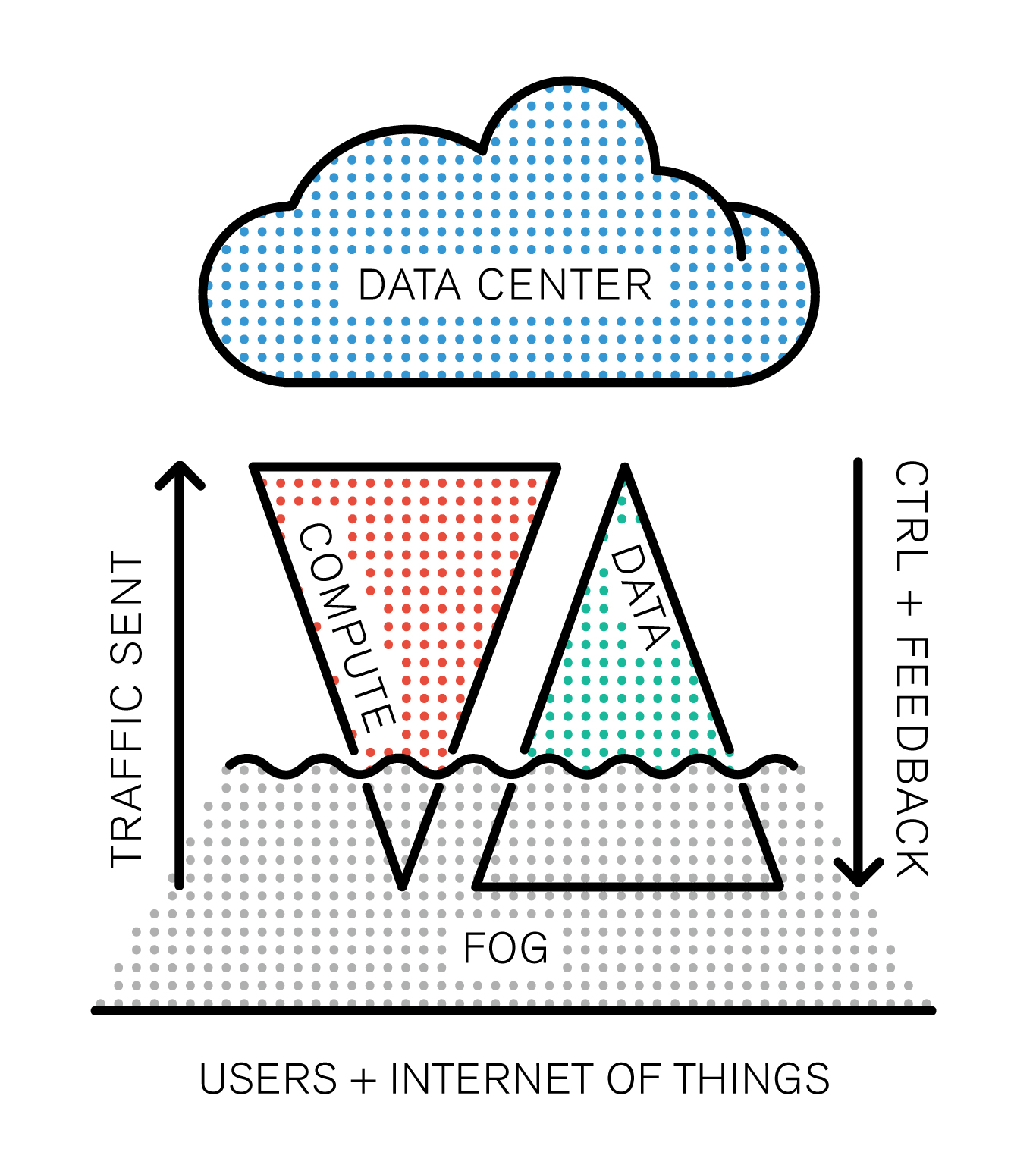
Data gravity is obviously what comes next after 20 years of anarchic internet content moderation. Have you ever heard of big data? Besides being the IT’s industry favorite buzzword alongside “cloud computing”, there’s a reason we don’t call it “infinite data”: the data is sorted byte after byte. The problem is, right now everything is sorted in the cloud, which means you have to push all this data up, just to get the distilled big data feedback down. If you think about your cell phone and the massive amounts of data it generates, sends out around the planet and receives in return, there’s something not quite energetically efficient about it.
For every search query, shopping cart filled, image liked and post reblog, our data travels thousands of kilometers to end up with a simple feedback sent to our device in return. In the long run, the network simply won’t be able to cope with these massive amounts of data transit. Data Gravity is the following concept: the closer the data is to the emission source, the heavier it is. If we take the analogy of the cloud, we could see data as a liquid which needs to be “evaporated” in order to be pushed to the cloud, where it can be compared and assimilated to big data, the correct answer being then pushed back to the device in return.
If fog computing is necessary, it is precisely because a solution is needed to distill the huge amounts of data generated “closer to the ground”. But under what physical form will it come to exist? Interestingly, it was difficult to find anybody in the field interested in this question. If the idea of creating data treatment facilities closer to users is popular, nobody seems to care about the fact that this “public infrastructure” is invisible. Indeed, the final aim, it seems, is to add a layer to the back-end of user technology, not to bring it closer to the user in terms of visibility. Rather the opposite: it seems we’re still all believing in security from opacity, even when the industry’s giants are going open-source. The amounts of money engaged in this new paradigm are colossal, Cisco’s Technology Radar assures (rather opaquely by the way).
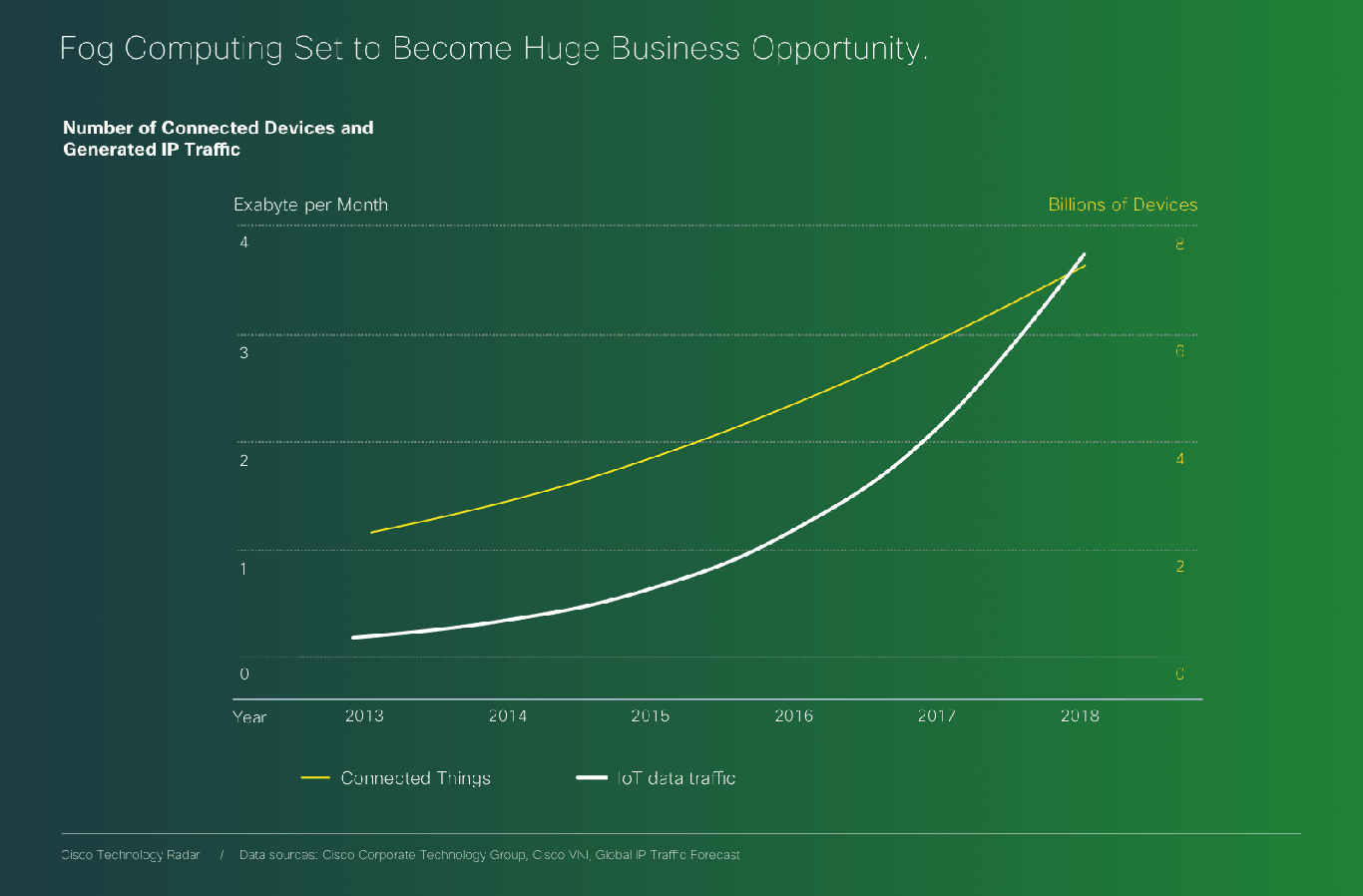
We will keep a close eye on the trends related to Fog and Cloud. However it is essential to stress that fog computing will not elude cloud computing. It is a new model indeed, but it is aimed to extend the cloud and decentralize it’s extremities rather than change the architecture of the whole infrastructure. While our main object of study remains the cloud, which is the final abstraction of computing in terms of distance to users (both physical and in terms of cognitive familiarity), it is also important for us to map out what comes in between both. As designers and architects, our work is to build intuitive ways of interacting with reality’s abstractions through objects. But @mccrory, who came up with the concept of data gravity also set up a definition of it as a “formula”, perhaps it helps.

––
Images credits:
Lucien Langton, I&IC Research Project
https://techradar.cisco.com/trends/Fog-Computing#prettyPhoto
http://datagravity.org/



0 Comments